(VBA)Midステートメントによる文字列操作
〔プログラムな?話〕 15:33 No Comment ツイート
<2019-11-19 修正あり>
先日公開したVBAの漢数字変換関数だが、最後の方に書いたとおり、文字列結合を&演算子でなくMidステートメントに置き換え、パフォーマンスの改善に挑戦してみた。
一般的(?)には馴染みが薄い手法で、自分もしばらくしたら忘れそうだ(というかちょっと忘れてた)ので、備忘録を兼ねて記事にしておく。
Midステートメントの要点
- 擬似的な文字列結合を実現できる。
- 一般的な&演算子による結合+代入より速い。
- 処理を遅くする要因に注意する。
- 「代入回数を減らせる」という強みを徹底的に生かすこと。
- 使えるか使えないかは、よく見極めること。
おまけ
1.Midステートメントを利用した疑似的な文字列結合
VB系では基本的に文字列は不変である。これはメモリ上の話で、ようするに「あるメモリ領域(アドレス)に格納された文字列は基本的に変更しない」ということであり、このため、変数に始めて文字列を格納する場合も、格納された文字列を変更する場合も、内部的には以下のまったく同じ動作を行っている。ついでに2つほど実験してみよう。
- 一連の文字列(リテラル)を作成する(式または関数等が使用されている場合、すべて文字にする)。
- ヒープ領域に、作成した文字列が入るだけの空きスペースを確保し、文字列を格納する。
- スタック領域に、文字列の先頭アドレスを格納する。
'実験1:変数のアドレスを調べる
Sub AddressCheckTest()
Dim n As Long
Dim s As String
'数値型の場合 出力結果
Let n = 0
Debug.Print VarPtr(n) ' 6155024 ←スタック領域のアドレス
Let n = n + 123
Debug.Print VarPtr(n) ' 6155024 ←値を変えてもアドレスは同じ
'文字列型の場合
Let s = "abc"
Debug.Print VarPtr(s) ' 6155020 ←スタック領域のアドレス
Debug.Print StrPtr(s) ' 324132324 ←ヒープ領域のアドレス(文字列実体)
Let s = s & "def"
Debug.Print VarPtr(s) ' 6155020 ←文字列を変えてもスタック領域のアドレスは同じだが…
Debug.Print StrPtr(s) ' 324132284 ←ヒープ領域のアドレスが変わっている
Let s = Left$(s, 2)
Debug.Print StrPtr(s) ' 324132084 ←文字を削っても変わる
Let s = "ghi"
Debug.Print StrPtr(s) ' 324133044 ←同じ文字数の別の文字列に入れ替えても変わる
Let s = "ghi"
Debug.Print StrPtr(s) ' 324131884 ←同じ文字列を再度代入しても変わる
End Sub
変数に実際どのようにデータが格納されているのかを調べるため、mima_ita氏のブログ「実験ぶろぐ(仮)試供品」の、Excel VBAでメモリをダンプしてみる記事のコードを参考にさせていただいた。
'実験2:変数の中身を調べる
Private Declare Function RtlMoveMemory Lib "kernel32.dll" _
(ByVal vDst As Any, ByVal vSrc As Any, ByVal vLen As Long) As Long
Sub DumpTest()
Dim s$
Let s = "〇一二三四五六七八九十"
Call DumpString(s) '・・・①
Debug.Print
Let s = Left$(s, Len(s) - 1) '1文字切り落とす
Call DumpString(s) '・・・②
End Sub
'メモリダンププロシージャ。参考:mima_ita氏 - 実験ぶろぐ(仮)試供品 https://needtec.exblog.jp/20613099/
Private Sub DumpString(ByRef str As String)
Debug.Print "スタックのダンプ(" & Hex$(VarPtr(str)) & "):"
Call DumpMemory(VarPtr(str), 4)
Debug.Print
Debug.Print "ヒープのダンプ(" & Hex$(StrPtr(str)) & "):"
Call DumpMemory(StrPtr(str), LenB(str))
End Sub
Private Sub DumpMemory(ByVal memOffset As Long, ByVal memSize As Long)
Dim memData() As Byte
Dim memHex As String * 2
Dim memAddr As String * 8
Dim dmpStr$
Dim i&, col_i&
ReDim memData(1 To memSize) As Byte
Call RtlMoveMemory(VarPtr(memData(1)), memOffset, memSize)
Let memAddr = Hex$(memOffset)
Let dmpStr = " " & memAddr & " "
For i = 1 To memSize
If col_i = 8 Then
Let col_i = 0
Let memAddr = Hex$((memOffset Xor &H80000000) + (i - 1) Xor &H80000000)
Let dmpStr = dmpStr & vbCrLf & " " & memAddr & " "
End If
Let memHex = String$(2 - Len(Hex$(memData(i))), "0") & Hex$(memData(i))
Let dmpStr = dmpStr & memHex & " "
Let col_i = col_i + 1
Next i
Debug.Print dmpStr
End Sub
実験2の結果:8バイトずつ
①
スタックのダンプ(CFE890): →変数のアドレス(スタック領域 0xCFE890)
CFE890 04 40 D5 11 →中身(アドレス11D54004が格納されている)
ヒープのダンプ(11D54004): →ヒープ領域のアドレス(0x11D54004)
11D54004 07 30 00 4E 8C 4E 09 4E →〇一二三(Unicode文字列)
11D5400C DB 56 94 4E 6D 51 03 4E →四五六七
11D54014 6B 51 5D 4E 41 53 →八九十
②(末尾の文字列を1文字切り取った)
スタックのダンプ(CFE890): →スタック領域のアドレスは①と同じ(0xCFE890)
CFE890 EC 3E D5 11 →中身(ヒープ領域のアドレス)は変わっている
ヒープのダンプ(11D53EEC): →ヒープ領域のアドレス(0x11D53EEC)
11D53EEC 07 30 00 4E 8C 4E 09 4E →〇一二三(Unicode文字列)
11D53EF4 DB 56 94 4E 6D 51 03 4E →四五六七
11D53EFC 6B 51 5D 4E →八九(十は切り取ったため含まれていない)
実験2を図示してみる。上段(青)の左の列が最初に代入された文字列(①)、右の列がLeft$関数で末尾の一文字を切り落とした文字列(②)が格納されたヒープ領域を表している。赤字で示した箇所は、メモリに格納されているデータが変更された、あるいは新規にデータが追加された箇所である。
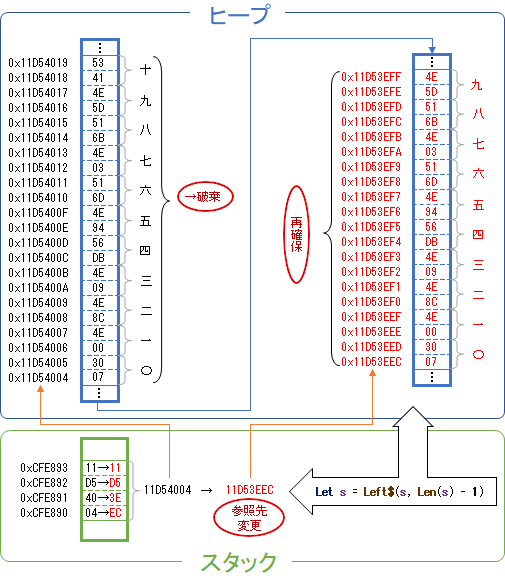
つまるところ文字列型は参照型である。そして図の右の列を見ればわかるとおり、代入命令が実行されると、すべての文字列実体を新たなヒープ領域に格納し、スタック領域では文字列実体の参照先を新たに確保したアドレスへ変更する。ヒープ領域の元の文字列実体のデータは、どこからも参照されなくなった時点で自動的に破棄される。関数や結合演算子等の使用の有無は関係なく、代入(Letステートメント)であれば必ずこうなる。
補足:一般的には'Let'を付けず代入のコードを書く人が多いが、それらは'Let'を省略したLetステートメントなので、'Let'を付けようが付けまいが代入である限り動作に変わりはない。
コード上は一文字だけの追加/削除の操作のつもりでも、実際にはすべての文字列を代入し直すのがLetステートメント(代入)である。数値型であろうがブール型であろうがこれは同じだが、それらと違い文字列は格納すべきデータ量が大きく、ヒープ領域にもスタック領域にもデータを格納する必要がある。当然、処理コストは高い。
補足:Microsoftのデータ型の説明では、String型のサイズは10バイト+文字列の長さ、とある。正確には「スタック領域:4バイト(ヒープ領域の参照先)+ヒープ領域:先頭4バイト(バイト単位の文字列長)+文字列リテラル+末尾2バイト(Null終端文字列)」。範囲の「約20億」は文字数(基本的に1文字=2バイト)。
そして、&演算子による結合処理も決して軽いとはいえない。どんどん文字を連結していくような処理は、重たい&演算とヒープ領域への文字列の再格納という二つの処理を繰り返し実行するということであり、付け加えれば文字列が長くなるほど領域の確保が大変になっていく、という問題も(たぶん)ある。
ここで登場するのがMidステートメントだが、これは変数に格納された文字列の一部を変更するステートメントで、内部的にはヒープ領域に格納された文字列をそのままに、文字列の一部または全部を変更する。また実験してみよう。
Sub AddressCheckTest2()
Dim s$
Let s = "〇一二三四五六七八九十"
Call DumpString(s) '・・・①
Debug.Print
Mid(s, 6) = "P"
Call DumpString(s) '・・・②
End Sub
結果:
①
スタックのダンプ(CFE890): →スタック領域 0xCFE890
CFE890 D4 F0 9B 1C →中身(ヒープ領域のアドレス 0x1C9BF0D4)
ヒープのダンプ(1C9BF0D4): →ヒープ領域 0x1C9BF0D4
1C9BF0D4 07 30 00 4E 8C 4E 09 4E →〇一二三
1C9BF0DC DB 56 94 4E 6D 51 03 4E →四五六七
1C9BF0E4 6B 51 5D 4E 41 53 →八九十
②('五'を'P'に置換した)
スタックのダンプ(CFE890): →スタック領域のアドレスは①と同じ(0xCFE890)
CFE890 D4 F0 9B 1C →中身(ヒープ領域のアドレス)も元のまま
ヒープのダンプ(1C9BF0D4): →ヒープ領域のアドレス(0x1C9BF0D4)
1C9BF0D4 07 30 00 4E 8C 4E 09 4E →〇一二三(Unicode文字列)
1C9BF0DC DB 56 50 00 6D 51 03 4E →四P六七 '94 4E'='五'が、'50 00'='P'になっている
1C9BF0E4 6B 51 5D 4E 41 53 →八九十
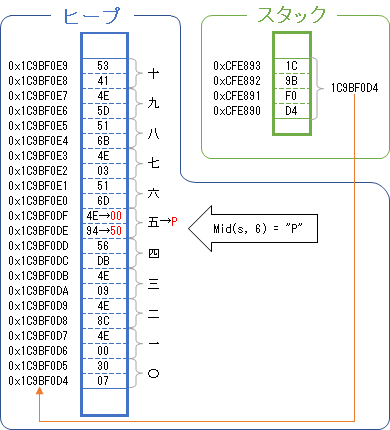
先ほどの代入(Letステートメント)と異なり、ヒープ領域の一部の文字列のみを上書きしている。
なお、メモリ領域ではUnicode(UTF-16)で実体が格納されており、半角/全角に関係なく1文字=2バイトとして扱うので、上記のように全角文字を半角文字に置き換えることも、その逆もできる(バイト単位で指定できるMidBステートメントも一応ある)。
ただし、元の文字列長を超えることはできない。
Sub MidTest()
Dim str$
Let str = "TEST"
Mid(str, 3) = "MPEST"
Debug.Print str '結果は「TEMP」
Mid(str, 5) = "EST" '実行時エラー!
End Sub
4行目は「TEST」の3文字目以降を別の文字列「MPEST」に置き換えるコードだが、元の文字列が4文字なので「MPEST」のうち先頭の2文字(MP)しか使えず、はみ出た文字(EST)は使われることなく捨てられてしまう。このステートメントができるのはあくまで「文字の置換」だけであり、文字列長を変えることはできない。先に書いたとおり半角文字も1文字=2バイト扱いなので、MidBステートメントでも全角6文字は半角12文字でなく半角6文字にしかなれない。また、当然だが元の文字列が4文字しかないのにMidステートメントで開始位置を5以降にすると実行時エラーとなる。
これらの点にさえ注意すれば、&演算による結合と同じことをMidステートメントで実現できる。あらかじめ結合後の文字列の長さと同じだけの長さを持つ適当な文字列を変数に格納しておき、Midステートメントで文字列を隙間なく置き換えていけばいい。
'※あらかじめ配列strArrに文字列が格納されているものとする。
'&演算による結合
For i = LBound(strArr) To UBound(strArr)
Let ret = ret & strArr(i) '文字列を結合
Next i
'Midステートメントによる結合
Let min = LBound(strArr)
Let max = UBound(strArr)
ReDim lenArr(min To max) As Long
For i = min To max 'すべての文字列長を調べる
Let lenArr(i) = Len(strArr(i)) '文字列を隙間なく配置するために必要
Let tLen = tLen + lenArr(i) 'すべての文字列が収まる長さを計算
Next i
Let ret = String$(tLen, vbNullChar) 'ヒープ領域を確保
Let p = 1
For i = min To max
Mid(ret, p) = strArr(i) '文字列を結合(置換)
Let p = p + lenArr(i) '次の文字列を結合(置換)する位置
Next i
見てのとおりコードはだいぶ膨らんでしまうが、メリットはある。
2.結合処理の速度
「&演算子で文字列を結合してヒープ領域に再格納」をN回繰り返すより、N個の文字列長を合計した長さの適当な文字列をヒープ領域に1回だけ格納してからMidステートメントで文字列を結合(隙間なく置換)していく方が、ずっと速い。
Sub JoinJoinTest()
Const x As Long = 200 '結合する文字列(要素)数。200~6400の間で検証。
Const LOOP_COUNT As Long = 10000 '処理が一瞬で終わってしまうので1万倍する
Dim strArr(1 To x) As String
Dim lenArr() As Long
Dim buf As String
Dim max&, min&, i&, j&, tLen&, p&
Dim pTime As Single
Let min = LBound(strArr)
Let max = UBound(strArr)
For i = min To max
Let strArr(i) = RandomString() 'ランダムな文字列を生成(コード省略)
Next i
'&演算子
Let pTime = Timer
For i = 1 To LOOP_COUNT
For j = min To max
Let buf = buf & strArr(j)
Next j
Let buf = "" '終了処理
Next i
Debug.Print Timer - pTime
'Midステートメント
Let pTime = Timer
For i = 1 To LOOP_COUNT
ReDim lenArr(min To max)
For j = min To max
Let lenArr(j) = Len(strArr(j))
Let tLen = tLen + lenArr(j)
Next j
Let buf = String$(tLen, vbNullChar)
Let p = 1
For j = min To max
Mid(buf, p) = strArr(j)
Let p = p + lenArr(j)
Next j
Let buf = "" '終了処理
Let tLen = 0
Next i
Debug.Print Timer - pTime
End Sub
| x= | 200個 | 400個 | 800個 | 1600個 | 3200個 | 6400個 |
|---|---|---|---|---|---|---|
| &演算子 | 0.23 | 0.53 | 1.41 | 4.45 | 18.67 | 89.43 |
| Midステートメント | 0.13 | 0.27 | 0.52 | 1.02 | 2.03 | 4.09 |
言い換えれば、変数のスタック領域の位置以外のすべてが置き換わる図1の処理より、ヒープ領域の一部のデータだけが置き換わる図2の処理の方が遥かに低コストである。結果、結合する文字列が多いほど、&演算子よりMidステートメントの方が高速に文字列を結合することができる。
ただ、当然ながら注意点はある。根本的には「文字列を置換するステートメントを文字列結合処理に流用する」ことになるので、処理が分かりづらくなるし、ほぼ何も考える必要のない&演算子による結合処理に比べ、考えなければならないことが増える。「Midステートメントの方が処理が早い」というほぼ唯一のメリットを潰さないようにしなければならない。
3.処理を遅くする要因
3-1.ヒープ領域をいかに確保するか
これまで書いたとおり、Midステートメントを実行する前に、最低でも2つの文字列(結合文字列、被結合文字列)の長さ以上に長い文字列型変数が存在していなければならない。これから結合するすべての文字列の長さの合計と等しい文字列長の文字列型変数があるのが最も望ましい。
先の例では、それを調べるために「文字列を総ナメして文字列長を合計する」という処理を挟んでいる。普通に考えたら二度手間である。この二度手間を避けたいのであれば、もっと他の方法で結合後の文字列長を把握できる手法を模索するか、あるいは上限を見積るしかない。ただし、確実な長さを見積れない場合は、文字列が領域をはみ出そうになった場合への対処や、逆に領域が余った時のトリミングなどの処置を講じる必要がある。
'はみ出そうな場合だけ文字列を再確保するコードの例
Const STR_LEN As Long = 24 '適当にはみ出ないと思われる文字数を指定
Let bufLen = STR_LEN
Let buf = String$(bufLen, vbNullChar)
For j = min To max
Let strLen = Len(strArr(j))
If p + strLen > bufLen Then
'はみ出そうになったら、元の文字列長×2+結合文字列長の長さにする
Let bufLen = bufLen * 2 + strLen
Let buf = buf & String$(bufLen + strLen, vbNullChar)
End If
Mid(buf, p + 1) = strArr(j)
Let p = p + strLen
Next j
If p < bufLen Then
Let buf = Left$(buf, p) '余分な領域があればトリミングする
End If
はみ出たときの領域拡張や最後のトリミングが代入、つまりヒープ領域の再確保になるため、パフォーマンスが若干落ちるのは言うまでもない。
3-2.文字列を隙間なく結合するには
とりもなおさず、Midステートメントによる(擬似的な)結合を実現するには、結合(置換)する文字列が重なったり隙間が空いたりしないように、ぴっちりと隙間なく変数(ヒープ領域)に詰め込む必要がある。
カウンタ変数を設け、結合した文字列の長さを順次加算することで次の結合位置を把握するのがオーソドックスかと思う。結合する文字列の長さが固定であれば、カウンタ変数を使わず「ループ回数×結合する文字列の長さ+1」で求めることもできる。大抵は難しい話ではない。
だが、結合する直前まで文字数が不明な場合は注意する必要がある。たとえば先のコードに、以下のように文字数が変わる整形などの処理を挟む場合だ。
Mid(buf, p) = ShapeString(strArr(j)) '文字列を加工する何かしらの関数
Midステートメントを実行するには、文字列結合(置換)の開始位置を把握しなければならない。どうすべきか?
文字列を一時変数に格納してからLen関数で文字数を調べたくなるが、そうすると代入(=ヒープ領域の確保)が発生するため、Midステートメントによる結合のアドバンテージの大部分が失われてしまう。
それよりずっとましな方法がある。例えばInStr関数。ヒープ領域の確保にはvbNullChar(ASCIIコード0、\0)を使用しており、\0が結合する文字列に含まれることがなければ、\0が最初に出現する位置が、次の文字列を結合する位置ということになる。\0は制御文字NUL(Null Pointerではない)であり、通常、文字列として使用することはない。
Mid(buf, p) = ShapeString(strArr(j))
Let p = InStr(buf, vbNullChar)
この他にもより良い手法がある。
4.メリットを活かす
とりもなおさずMidステートメントを使用するメリットは、文字列型変数への再代入を経ずに文字列を変更できることであり、ひいては素早い文字列操作ができることに尽きる。であれば、これをとことん突き詰めるべきだろう。
仮に、先ほど挙げたShapeString関数を含めた処理が以下のようなものだったとする。
Let buf = String$(ABSOLUTE_LIMIT, vbNullChar) 'オーバーフローは発生しない前提の例
Let p = 1
For j = min To max
Mid(buf, p) = ShapeString(strArr(j))
Let p = p + InStr(buf, vbNullChar, p) '\0の出現位置=次の文字列の結合位置
Next j
Let buf = Left$(buf, p)
Function ShapeString(ByVal src As String) As String
If Len(src) > 0 Then
'~文字列を加工する処理~
Let ShapeString = src
End If
End Sub
上記のShapeString関数内では、ヒープ領域への文字列の格納が最低でも2回発生する。書き方は色々あるが、文字数が変わるレベルの加工を行うという前提の上では、①加工用の変数に文字列を渡す(ヒープ領域確保1回目)、②加工後の文字列を戻り値として渡す(ヒープ領域確保2回目)、という構造は根本的に避けようがない。
※引数を参照渡しにしShapeStringに文字列を代入してから文字列加工を行うようにコードを変えたとしても、①加工用の変数(ShapeString)に文字列を渡し、②文字数が変わるレベルの加工を行う(=代入が発生する)、となるだけであって、コストの低減にはつながらない。
だが、改善の余地がないわけではない。前のセクションで挙げた問題点は要するに「呼び出し元で加工後の文字数を把握できない」ということだった。
もしこの関数自体を見直せるなら、呼び出し元に文字列だけでなく文字数まで返せるようにするとか、処理を呼び出し元か関数側に移すとかの改善策が考えられる。以下はその一例。
Let buf = String$(ABSOLUTE_LIMIT, vbNullChar) 'オーバーフローは発生しない前提の例
For j = min To max
Call ShapeString(strArr(j), buf, p)
Next j
Let buf = Left$(buf, p)
Sub ShapeString(ByVal src As String, ByRef dst As String, ByRef cnt As Long)
If Len(src) > 0 Then
'~文字列を加工する処理~
Mid(dst, cnt + 1) = src
Let cnt = cnt + Len(src)
End If
End Sub
呼び出し元の変数を参照渡しで渡して直接書き換えてしまえばいい。こうすればわざわざ呼び出し元でInStr関数を使ったりして調べる必要はないし、戻り値に文字列を代入する必要もない。
なお、1回しか呼ばれておらず他のプログラムでも利用されていないようなプロシージャなら、そもそもプロシージャとして分けておく必要がないので、呼び出し元のコードにまとめてしまっていい。
5.まとめ
上記のようなことをだらだらと悩みながらコードを書き上げたが、結局のところ「どこまでパフォーマンスを追求すべきか」「再利用性や保守性をどこまで保つべきか」ということを、VBAというマクロ言語で公開範囲がいくら狭いとしても考えなければならない、ということに思い至った。
具体的には、ここまでのパフォーマンス改善が必要なものか。改善される見込みがあるか。コードの汎用性はどうか。自分が後から見返して理解できるか。(他人がコードを触る前提の場合は)他人が理解できるか。などなど。
例えば、より改善が必要な(動作の重い)別の処理があるなら当然そちらの改善を優先すべきだし、結合回数が元々少ない処理ではこれによるパフォーマンス改善など微々たるものだ。これまで書いた手法を用いて、20000個の文字列を1つに結合する処理を改善するのと、50個の文字列の結合を400回繰り返す処理を改善するのとでは、改善の度合いが異なる。言うまでもなく前者に比べ後者は効果が少ない(400個の文字列を生成する必要が本当にあるのかを見直した方がいい気がする)。
また、先に挙げた文字列を加工する関数を挟む例で、関数側の処理が複雑すぎたり呼び出しが入り組んでいたりなどして修正が困難な場合や、そもそも手を付けることができない場合などには、すっぱり諦めて別の部分に目を向けた方が色々と健全だろう。
あと、言うまでもないが、数値を結合するのであれば文字列として処理するより数値として処理した方が全体的に速い。が、32ビット版のOfficeのLong型は4バイト(符号付き32ビット整数)なので、あまり大きな数字は扱えないことに注意すること。
おまけ - Format$関数について
あれこれとパフォーマンスの検証をしていて気づいたことだが、Format$関数の動作がとにかく重い。Format$関数を用いた0埋めや3桁カンマ区切りの処理で速度を比較してみた。
'0埋め速度比較
Let src = "12345" '変換元文字列
Let sze = 10 '0埋め桁数
'テスト① ・・・Format$関数
Let dst = Format$(src, String$(sze, "0"))
'テスト② ・・・結合(&演算子)
Let dst = String$(sze - Len(src), "0") & src
'テスト③ ・・・結合(Midステートメント)
Let dst = String$(sze, "0")
Mid(dst, sze - Len(src) + 1) = src
'カンマ区切り速度比較
Let src = "1234567890" '変換元文字列
'テスト① ・・・Format$関数
Let dst = Format$(src, "#,###")
'カンマ区切テスト② ・・・分解→結合(&演算子)
Let sze = Len(src)
Let ptr = sze - Int((sze - 1) / 3) * 3 '先頭の3組(3文字と限らない)の文字数
Let dst = Left$(src, ptr) '先頭の3組(3文字と限らない)を格納
For i = ptr + 1 To sze - 2 Step 3
Let dst = dst & "," & Mid$(src, i, 3) 'カンマ+3組を順次結合
Next i
'カンマ区切テスト③ ・・・分解→結合(Midステートメント)
Let sze = Len(src)
Let com = Int((sze - 1) / 3) '挿入するカンマの数
Let dst = String$(sze + com, vbNullChar) '「元の文字列長+カンマの数」分の空文字列
Let ptr = sze - com * 3 '先頭の3組(3文字と限らない)の文字数
Mid(dst, 1) = Left$(src, ptr) '先頭の3組(3文字と限らない)を配置(置換)
Let ptr = ptr + 1 '次の結合(置換)位置
For i = ptr To sze - 2 Step 3
Mid(dst, ptr) = "," 'カンマ+3組を順次結合(置換)
Mid(dst, ptr + 1) = Mid$(src, i, 3)
Let ptr = ptr + 4
Next i
| パターン | テスト①(Format$) | テスト②(&結合) | テスト③(Mid結合) |
|---|---|---|---|
| 0埋め | 2.906250 | 0.484375 | 0.343750 |
| カンマ区切り | 2.312500 | 2.031250 | 1.562500 |
…どう考えても、ユーザーのコードより組み込み関数の方がパフォーマンスで劣るのが釈然としない(昔からその手の話題はあったとはいえ)。Format関数はかなり広汎な書式をサポートしてるから恐らく図体が重いのだろう、と考えておくことにする。
なお、見ればわかるとおりコード量は増える。0埋めはともかく桁区切りは1行が11行になったりするので、注意すること。
2019-10-18 一部修正
画像を追加。併せて字句をちょこちょこと修正したりリンクを追加したり。
2019-10-29 一部修正
字句の修正、追記など。
2019-10-31 追記・一部修正
おまけを追記。目次を修正。
2019-11-19 修正
イメージ図に若干誤りがあったため画像を差し替え。