(VBA)固定長文字列について
〔プログラムな?話〕 13:46 No Comment ツイート
<2019-11-25 修正あり>
VBAにおける文字列型変数には可変長文字列と固定長文字列があり、以前の記事で触れたMidステートメントを利用した文字列結合は、可変長文字列を使用している。
ところで、Microsoftのリファレンスにはこんなことが書いてある。
- 「Micsoft Docs - スタック領域が不足しています (エラー 28)」より抜粋
-
スタックとは、実行中のプログラムの需要に応じて動的に増減されるメモリの作業領域です。 このエラーの原因と解決策を以下に示します。
- (中略)
- 固定長の文字列が多すぎます。プロシージャ内の固定長文字列は、より迅速にアクセスできますが、文字列データそのものがスタックに配置されるため、可変長文字列よりも多くのスタックスペースを使用します。(以下略)
固定長文字列はスタック領域に文字列リテラルを格納するため、可変長文字列より高速にアクセスできるらしい。確かに文字列の長さが固定であれば、文字列リテラルを格納するメモリ領域を変える必要がない=アドレスを固定できるので、参照型であることを辞め数値型などの他の値型と同様、スタック領域に直接データを保持するようにすれば、パフォーマンスの向上が図れるだろう。
ところが実際に固定長文字列と可変長文字列の二つの変数に単純な代入や簡単な(LeftやReplaceや結合などの)文字列操作等を行わせて処理速度を比較すると、固定長文字列が可変長文字列に処理速度で勝ることは少ない。
その上固定長文字列には最大65,526文字という上限があるし、他にも様々な制約がある。
もっとも、固定長文字列の使い方を自分が熟知していないというだけであって、少なくとも自分の今の使い方では固定長文字列をパフォーマンス向上に使うことができない、ということだろうと思う。よし。なんだか分からんけど使えないってことでいいや。終わり。
…とは言え、単純な代入ですら可変長文字列より固定長文字列の方が遅い原因が分からずにモヤモヤしたままでいるのも嫌だったので、自分なりに検証・予想してみた。
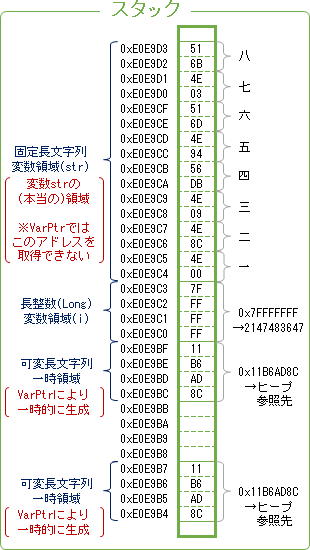
Microsoft公式で書かれていることが正しければ、固定長文字列はスタック領域に文字列を直接格納しているはずであり、もしそうなら公式に書かれているとおり「より迅速にアクセスできる」はずなのだ。検証するために先の記事で書いたメモリダンプ(DumpString・DumpMemory)を利用して固定長文字列のメモリをダンプしてみたら、なんだか不思議なことになった。
Dim str As String * 8
Dim i As Long
Let i = 2147483647 'Long型の最大値(0x7FFFFFFF)
Let str = "一二三四五六七八"
Debug.Print "参照:" & vbCrLf & " " & Hex$(VarPtr(str)) _
& "-> " & Hex$(VarPtr(ByVal str))
Debug.Print vbCrLf & "スタックのダンプ(24byte):"
Call DumpMemory(VarPtr(str), 8) 'スタック領域(4byte)
Call DumpMemory(VarPtr(str) + 8, 16) 'スタック領域(16byte)
Debug.Print vbCrLf & "ヒープのダンプ(16byte):"
Call DumpMemory(StrPtr(str), LenB(str)) 'ヒープ領域
参照:
E0E9B4-> 11B6AD8C →なぜかスタックのアドレスがずれる
スタックのダンプ(24byte):
E0E9BC 8C AD B6 11 FF FF FF 7F 0x11B6AD8C →ヒープのアドレス…のはず。 0x7FFFFFFF →変数iの中身
E0E9C4 00 4E 8C 4E 09 4E DB 56 一二三四 →スタックに格納された文字列リテラル
E0E9CC 94 4E 6D 51 03 4E 6B 51 五六七八
ヒープのダンプ(16byte):
11B6AECC 00 4E 8C 4E 09 4E DB 56 一二三四 →スタックに格納されたアドレスと異なる
11B6AED4 94 4E 6D 51 03 4E 6B 51 五六七八
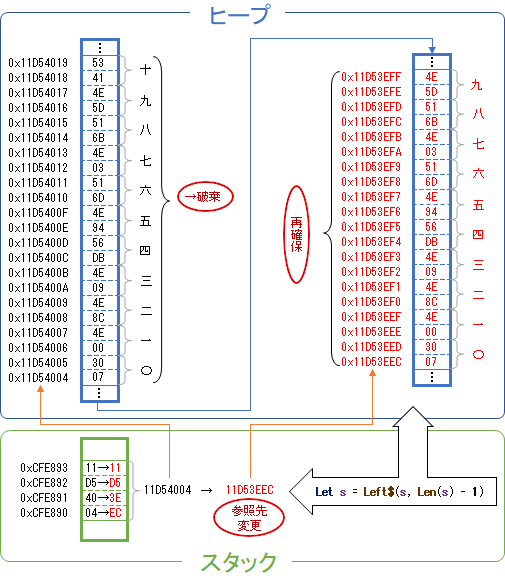
VarPtr関数で取得したアドレスに格納されたデータをダンプすると、まず最初の4バイトにヒープへのアドレスらしきデータが見受けられる。だが、StrPtr関数で取得したヒープ領域のアドレスとは異なる。そして次の4バイトは長整数型変数iのデータ(0x7FFFFFFF=2147483647)があり、更にその先に文字列リテラルが格納されている。つまり、「ヒープ領域のアドレス(と思わしきもの)が格納されている領域」と「文字列リテラルが格納されている領域」は必ずしも隣接しておらず(他のデータが間に入っている)、一連のデータではない。自作のDumpStringでスタックとヒープを出力すると、スタック領域に格納されたヒープ領域のアドレスとStrPtr関数が指し示すアドレスは整合する。そして、VarPtr関数・StrPtr関数・DumpMemoryなどでアクセスするたび、スタック領域に格納されたヒープ領域のアドレスが変動する。
まとめると以下のとおり。
- スタック領域に文字列リテラルが見受けられるが、VarPtr関数で取得したアドレスはそこに行き着かない。
- VarPtr関数の結果(スタック領域のアドレス)がなぜか変わる。
- VarPtr関数で取得したスタック領域のアドレスには、スタック領域に格納されたヒープ領域のアドレスが入っている。
- StrPtr関数で取得するヒープ領域のアドレスは毎回変わる(文字列型以外の変数をStrPtrしたときと同じ)。
- なぜか可変長文字列を使ったときよりパフォーマンスが悪い。
色々考えたが、VarPtr関数では固定長文字列のスタック領域のアドレスを取得できないのではないか、という予測を立てた。そもそもVarPtr・StrPtr・ObjPtr関数自体が隠し関数であり、動作が保証されているものではない。StrPtr関数は渡された変数を可変長の文字列型とみなす(ヒープ領域に値がない場合は値をヒープ領域に格納する)ので固定長文字列をヒープ領域に格納し直すのはわかるが、VarPtr関数もまた固定長文字列を正しく処理できず(あるいは可変長文字列と固定長文字列の区別がつかず)、可変長文字列と同じデータ構造に一時的に変換しているのではないか。つまり以下のようなイメージだ。
DumpMemory・DumpString関数の結果がおかしくなるのも、引数に渡された固定長文字列が可変長文字列に都度変換されているからだと思われる。Functionステートメント、Subステートメントの説明にあるとおり、引数に指定できる文字列型は可変長文字列のみであり、またDeclareステートメントの注意書きにあるとおり、固定長文字列を渡しても可変長文字列に変換されているのだろう。つまり、固定長文字列のままプロシージャの引数に渡すことはできないということであり、これはユーザー定義のプロシージャに限らない、ということではないか。
以上のことから考えるに、固定長文字列は構造的にパフォーマンスが高いはずだが、大部分のステートメントや組み込み関数等が可変長文字列を前提としているため、ことあるごとに暗黙的に可変長文字列に変換されてしまい、結果として可変長文字列よりパフォーマンスが落ちているのではないだろうか。
もしそうだとすると、Midステートメントとの相性がいいのも頷ける。
'置換処理速度の比較(200万回繰り返し)
Dim src As String
Let src = "〇一二三四五六七八九十"
'可変長文字列の場合
Dim dst As String
'固定長文字列の場合
Dim dst As String * 11
'Replace$関数による置換
Let dst = Replace$(src, "十", "P")
'Midステートメントによる置換
Let dst = src
Let num = InStr(src, "十")
If num > 0 Then
Mid(dst, num) = "P"
End If
| パターン | 可変長文字列 | 固定長文字列 |
|---|---|---|
| Replace$関数 | 1.6992190 | 2.0664060 |
| Midステートメント | 0.2773438 | 0.2226563 |
表の上段の結果のとおり、Replace関数などの文字列操作関数や代入(Letステートメント)では、固定長文字列のパフォーマンスは落ちる。まず、Letステートメントは「データの総入れ替え」なので、固定長文字列であっても可変長文字列と同様にすべての文字列が入れ替わるという点では、固定長文字列にアドバンテージはない。他にそれぞれで行われる処理としては、可変長文字列の場合は①文字列の手前4バイトに文字列長を格納、②文字列末尾2バイトにヌル終端文字列を格納、③スタック領域に参照先を格納。固定長文字列の場合は①文字列が領域より長い場合は文字列を切り捨て、②文字列が領域より短い場合は空白を挿入。もしかすると固定長文字列に限り更に何らかのひと手間(データ構造の変換またはデータ移動等)があり、文字列リテラルの格納に手間がかかっている、ということもあるかもしれない。
加えて、上記のコードではInStr関数の引数に可変長文字列を指定しているが、実はここを固定長文字列に変えると処理が遅くなる。先述のとおり文字列操作系の関数が固定長文字列を想定しておらず、引数に指定された固定長文字列を一旦可変長文字列と同じデータ構造に変換している、などといった手間が生じていると思われる。
つまり、固定長文字列を普通に使用したのでは、読み込み(関数の引数)にも書き込み(Let)にも何かしら手間が生じパフォーマンスが低下してしまう。
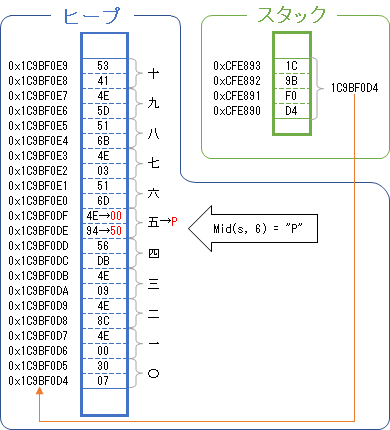
他方、Midステートメントによる置換では、固定長文字列に分がある。参照型である可変長文字列と異なり、固定長文字列はスタックに直接文字列リテラルを保持しているので、メモリ領域の文字列を直接置き換えるMidステートメントではその差が現れるのだろう。
言い方を変えれば、Midステートメントは文字列操作関数やLetステートメント等とは違い(可変長文字列への変換等を行わず)、スタック領域に格納されている文字列リテラルを直接変更しているのだと思う。
つまり、使い方次第で固定長文字列の本来のパフォーマンスを引き出すこともできる。
が。
結局のところ、以前書いた漢数字変換関数などには固定長文字列を使わなかった。
固定長文字列の宣言(Dimステートメント)の文字列長の指定は定数式でなければならない、つまりあらかじめ決め打ちしておく必要があるし、コードの途中で文字列長を変えることもできない。定数式に関しては定数を増やせばいいがこれ以上増やしたくなかったし、コードの柔軟性とか固定長文字列にできる変数とすべきでない変数の選別とかパフォーマンスの検証とかなんかそういうのを考えて導入しなかった。
まとめ - VBAにおける固定長文字列
- 文字列が直接スタック領域に格納される(数値型やブール型等と同様)。
- 最長65,526文字まで(スタック領域を食い潰すので注意)。
- ユーザー定義のプロシージャや組み込み関数の引数に固定長文字列のまま指定することはできず、可変長文字列に変換される(このためVarPtr関数の引数に固定長文字列を指定しても正しいアドレスを取得できない)。
- プロシージャの戻り値の型に固定長文字列を指定することもできない(Property Get、Functionなど)。
- 可変長文字列と同じ扱い方で固定長文字列を扱うと、パフォーマンスが落ちる傾向がある。
- Midステートメントのように直接アクセスするなど、扱い方次第では可変長文字列より早くなる。
- 文字列長は定数式(定数またはリテラル)で指定しなければならないので注意すること。
2019-11-15 追記
なお、上記記事やこれまでのVBA関係の記事は32ビットOffice環境を前提としている。
2019-11-21 追記
画像とまとめを追記。
2019-11-25 修正
画像が誤っていたため差し替え。